搜索到
80
篇与
的结果
-
![centos系统 yum配置 初始化脚本]() centos系统 yum配置 初始化脚本 #删除系统原有的YUM源 rm -rf /etc/yum.repos.d/* #配置阿里云基础源(base,extras,updates) curl https://mirrors.aliyun.com/repo/Centos-7.repo -o /etc/yum.repos.d/CentOS-Base.repo #配置阿里云EPEL源 curl https://mirrors.aliyun.com/repo/epel-7.repo -o /etc/yum.repos.d/epel.repo #安装基本的软件包 yum install -y wget curl vim-enhanced git net-tools bash-completion #关闭防火墙 systemctl stop firewalld.service systemctl disable firewalld.service
centos系统 yum配置 初始化脚本 #删除系统原有的YUM源 rm -rf /etc/yum.repos.d/* #配置阿里云基础源(base,extras,updates) curl https://mirrors.aliyun.com/repo/Centos-7.repo -o /etc/yum.repos.d/CentOS-Base.repo #配置阿里云EPEL源 curl https://mirrors.aliyun.com/repo/epel-7.repo -o /etc/yum.repos.d/epel.repo #安装基本的软件包 yum install -y wget curl vim-enhanced git net-tools bash-completion #关闭防火墙 systemctl stop firewalld.service systemctl disable firewalld.service -
![使用代理IP和访问控制策略提高爬虫效率]() 使用代理IP和访问控制策略提高爬虫效率 前言在进行网络爬虫工作时,经常会遇到被目标网站封禁的情况,尤其是频繁请求同一页面或同一接口时。为了解决这个问题,我们可以使用代理IP和访问控制来提高爬虫的稳定性和可靠性。本文将介绍如何使用代理IP和访问控制来优化爬虫的效率。一、爬虫代理IP的使用爬虫使用代理IP可以隐藏真实的访问源,模拟不同的用户请求,减少被封禁的可能性。以下是使用代理IP的一般步骤:1. 获取可用代理IP可以从代理IP提供商购买或使用免费的代理IP。免费的代理IP质量较低,容易被封禁,建议购买稳定可靠的代理IP。2. 验证代理IP的可用性通过发送请求到目标网站,验证代理IP是否可用。一般可以使用requests库发送HTTP请求,并根据返回的状态码来判断代理IP的有效性。import requests proxy = {'http': 'http://your_proxy_ip:your_proxy_port'} try: response = requests.get(url, proxies=proxy, timeout=5) if response.status_code == 200: print('代理IP可用') else: print('代理IP无效') except Exception as e: print('请求失败', e)3. 设置代理IP在爬虫程序中使用代理IP,使用requests库提供的proxies参数,将代理IP传入访问请求中,从而实现了使用代理IP请求网页的功能。import requests proxy = {'http': 'http://your_proxy_ip:your_proxy_port'} try: response = requests.get(url, proxies=proxy, timeout=5) if response.status_code == 200: print(response.text) else: print('请求失败') except Exception as e: print('请求失败', e)二、访问控制除了使用代理IP,访问控制也是一个重要的优化策略。通过设置访问频率和请求间隔,可以避免对目标网站造成过大的访问压力,进而减少被封禁的风险。以下是一些常用的访问控制方法:1. 设置请求头信息在发送请求时,设置User-Agent、Referer等请求头信息,模拟正常的用户请求。可以通过随机选择不同的User-Agent来增加请求的随机性。import requests headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3', 'Referer': 'http://www.example.com' } try: response = requests.get(url, headers=headers, timeout=5) if response.status_code == 200: print(response.text) else: print('请求失败') except Exception as e: print('请求失败', e)2. 设置访问频率和请求间隔在爬取过程中,设置合理的访问频率和请求间隔,避免过于频繁的请求。可以使用time模块的sleep方法来控制请求间隔时间。import requests import time headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3' } for i in range(10): try: response = requests.get(url, headers=headers, timeout=5) if response.status_code == 200: print(response.text) else: print('请求失败') except Exception as e: print('请求失败', e) time.sleep(5) # 每隔5秒发送一次请求三、综合应用在实际爬虫工作中,我们通常同时使用代理IP和访问控制来提高爬取的稳定性和可靠性。以下是一个综合应用的示例:import requests import random import time proxy_list = ['http://your_proxy_ip1:your_proxy_port1', 'http://your_proxy_ip2:your_proxy_port2'] # 代理IP列表 headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3', 'Referer': 'http://www.example.com' } for i in range(10): proxy = {'http': random.choice(proxy_list)} try: response = requests.get(url, headers=headers, proxies=proxy, timeout=5) if response.status_code == 200: print(response.text) else: print('请求失败') except Exception as e: print('请求失败', e) time.sleep(5) # 每隔5秒发送一次请求上述示例中,我们使用了随机选择代理IP的方式来模拟不同的访问源,同时设置了请求头信息和请求间隔。这样可以有效地提高爬虫的稳定性和可靠性。总结使用代理IP和访问控制是提高爬虫稳定性和可靠性的常用方法。通过使用不同的代理IP和设置合理的访问频率和请求间隔,我们可以减少被封禁的风险,提高爬虫的效率和成功率。在实际工作中,需要根据目标网站的具体情况来选择合适的代理IP和访问控制策略。在使用代理IP时,需要注意代理IP的质量和稳定性,避免使用低质量的代理IP,以免影响爬虫的效果。另外,使用代理IP和访问控制时也需要遵守相关法律法规和网站的使用规定,以免违规行为带来的法律风险和不良影响。
使用代理IP和访问控制策略提高爬虫效率 前言在进行网络爬虫工作时,经常会遇到被目标网站封禁的情况,尤其是频繁请求同一页面或同一接口时。为了解决这个问题,我们可以使用代理IP和访问控制来提高爬虫的稳定性和可靠性。本文将介绍如何使用代理IP和访问控制来优化爬虫的效率。一、爬虫代理IP的使用爬虫使用代理IP可以隐藏真实的访问源,模拟不同的用户请求,减少被封禁的可能性。以下是使用代理IP的一般步骤:1. 获取可用代理IP可以从代理IP提供商购买或使用免费的代理IP。免费的代理IP质量较低,容易被封禁,建议购买稳定可靠的代理IP。2. 验证代理IP的可用性通过发送请求到目标网站,验证代理IP是否可用。一般可以使用requests库发送HTTP请求,并根据返回的状态码来判断代理IP的有效性。import requests proxy = {'http': 'http://your_proxy_ip:your_proxy_port'} try: response = requests.get(url, proxies=proxy, timeout=5) if response.status_code == 200: print('代理IP可用') else: print('代理IP无效') except Exception as e: print('请求失败', e)3. 设置代理IP在爬虫程序中使用代理IP,使用requests库提供的proxies参数,将代理IP传入访问请求中,从而实现了使用代理IP请求网页的功能。import requests proxy = {'http': 'http://your_proxy_ip:your_proxy_port'} try: response = requests.get(url, proxies=proxy, timeout=5) if response.status_code == 200: print(response.text) else: print('请求失败') except Exception as e: print('请求失败', e)二、访问控制除了使用代理IP,访问控制也是一个重要的优化策略。通过设置访问频率和请求间隔,可以避免对目标网站造成过大的访问压力,进而减少被封禁的风险。以下是一些常用的访问控制方法:1. 设置请求头信息在发送请求时,设置User-Agent、Referer等请求头信息,模拟正常的用户请求。可以通过随机选择不同的User-Agent来增加请求的随机性。import requests headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3', 'Referer': 'http://www.example.com' } try: response = requests.get(url, headers=headers, timeout=5) if response.status_code == 200: print(response.text) else: print('请求失败') except Exception as e: print('请求失败', e)2. 设置访问频率和请求间隔在爬取过程中,设置合理的访问频率和请求间隔,避免过于频繁的请求。可以使用time模块的sleep方法来控制请求间隔时间。import requests import time headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3' } for i in range(10): try: response = requests.get(url, headers=headers, timeout=5) if response.status_code == 200: print(response.text) else: print('请求失败') except Exception as e: print('请求失败', e) time.sleep(5) # 每隔5秒发送一次请求三、综合应用在实际爬虫工作中,我们通常同时使用代理IP和访问控制来提高爬取的稳定性和可靠性。以下是一个综合应用的示例:import requests import random import time proxy_list = ['http://your_proxy_ip1:your_proxy_port1', 'http://your_proxy_ip2:your_proxy_port2'] # 代理IP列表 headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3', 'Referer': 'http://www.example.com' } for i in range(10): proxy = {'http': random.choice(proxy_list)} try: response = requests.get(url, headers=headers, proxies=proxy, timeout=5) if response.status_code == 200: print(response.text) else: print('请求失败') except Exception as e: print('请求失败', e) time.sleep(5) # 每隔5秒发送一次请求上述示例中,我们使用了随机选择代理IP的方式来模拟不同的访问源,同时设置了请求头信息和请求间隔。这样可以有效地提高爬虫的稳定性和可靠性。总结使用代理IP和访问控制是提高爬虫稳定性和可靠性的常用方法。通过使用不同的代理IP和设置合理的访问频率和请求间隔,我们可以减少被封禁的风险,提高爬虫的效率和成功率。在实际工作中,需要根据目标网站的具体情况来选择合适的代理IP和访问控制策略。在使用代理IP时,需要注意代理IP的质量和稳定性,避免使用低质量的代理IP,以免影响爬虫的效果。另外,使用代理IP和访问控制时也需要遵守相关法律法规和网站的使用规定,以免违规行为带来的法律风险和不良影响。 -
![电影天堂全部类型下的所有电影]() 电影天堂全部类型下的所有电影 # -*- coding:utf-8 -*- # @time:2025/7/9 9:50 # @author:张旭辉 # @file : 1-获取全国城市.py # @编辑器: PyCharm import time # 时间 import random # 随机数 import re # 正则表达式 一套规则 用于匹配符号条件的记录 from lxml import etree # 从lxml中导入etree 目的是为了解析网页源码 # 从myhttp.py文件中 导入模块 具体 函数是get_data from myhttp import get_data # 准备url 1 就是喜剧片的类型 第1页 2 3 for i in range(0,21): url = f"https://www.dytt8899.com/{i}/index.html" print(url) # 发送请求 response = get_data(url) # 获取数据 # 加载源码 html = etree.HTML(response.text) # xpath解析 # 获取当前类型电影的最大页码 类型转成int pagemax = int(html.xpath("//select/option[last()]/text()")[0].split(" ")[1]) for page in range(1,pagemax+1): # time.sleep(random.randint(1,10))# 睡觉 单位秒 随机范围1-10秒 if page == 1: url = f"https://www.dytt8899.com/{i}/index.html" else: url = f"https://www.dytt8899.com/{i}/index_{page}.html" # 再次发送请求 # 发送请求 response = get_data(url) # 获取数据 # 加载源码 html = etree.HTML(response.text) # 从第page页中取电影类型 type = ''.join(re.findall(r'[\u4e00-\u9fa5]+', html.xpath("//h1//font/text()")[0])) # 当前页的全部电影数据30条 tables = html.xpath("//div[@class='co_content8']/ul//table") print(f"============================正在下载【{type}】第{page}/{pagemax}页数据================================") with open(f"data/{type}.txt","a",encoding="utf-8") as f: f.write(f"\n---------------------------------{page}/{pagemax}-----------------------------------------\n") for table in tables: date = table.xpath(".//tr[3]/td[2]/font[1]/text()")[0] # 日期 score = table.xpath(".//tr[3]/td[2]/font[2]/text()")[0] # 评分 score = re.sub(r'\s+', ' ', score).strip() # 去了回车换行空格之后的评分 title_director = table.xpath(".//tr[4]/td[1]/p[1]/text()")[0] # 片名 导演 title_director = re.sub(r'\s+', ' ', title_director).strip() # 去了回车换行空格之后的 片名 导演 print(date,score,title_director) # 打印 f.write(f"{date} {score} {title_director}\n") # 写入文件 f.write(f"\n---------------------------------{page}-----------------------------------------\n") print(f"============================【{type}】第{page}/{pagemax}页数据下载完成================================") print(f"{type}下载完成")
电影天堂全部类型下的所有电影 # -*- coding:utf-8 -*- # @time:2025/7/9 9:50 # @author:张旭辉 # @file : 1-获取全国城市.py # @编辑器: PyCharm import time # 时间 import random # 随机数 import re # 正则表达式 一套规则 用于匹配符号条件的记录 from lxml import etree # 从lxml中导入etree 目的是为了解析网页源码 # 从myhttp.py文件中 导入模块 具体 函数是get_data from myhttp import get_data # 准备url 1 就是喜剧片的类型 第1页 2 3 for i in range(0,21): url = f"https://www.dytt8899.com/{i}/index.html" print(url) # 发送请求 response = get_data(url) # 获取数据 # 加载源码 html = etree.HTML(response.text) # xpath解析 # 获取当前类型电影的最大页码 类型转成int pagemax = int(html.xpath("//select/option[last()]/text()")[0].split(" ")[1]) for page in range(1,pagemax+1): # time.sleep(random.randint(1,10))# 睡觉 单位秒 随机范围1-10秒 if page == 1: url = f"https://www.dytt8899.com/{i}/index.html" else: url = f"https://www.dytt8899.com/{i}/index_{page}.html" # 再次发送请求 # 发送请求 response = get_data(url) # 获取数据 # 加载源码 html = etree.HTML(response.text) # 从第page页中取电影类型 type = ''.join(re.findall(r'[\u4e00-\u9fa5]+', html.xpath("//h1//font/text()")[0])) # 当前页的全部电影数据30条 tables = html.xpath("//div[@class='co_content8']/ul//table") print(f"============================正在下载【{type}】第{page}/{pagemax}页数据================================") with open(f"data/{type}.txt","a",encoding="utf-8") as f: f.write(f"\n---------------------------------{page}/{pagemax}-----------------------------------------\n") for table in tables: date = table.xpath(".//tr[3]/td[2]/font[1]/text()")[0] # 日期 score = table.xpath(".//tr[3]/td[2]/font[2]/text()")[0] # 评分 score = re.sub(r'\s+', ' ', score).strip() # 去了回车换行空格之后的评分 title_director = table.xpath(".//tr[4]/td[1]/p[1]/text()")[0] # 片名 导演 title_director = re.sub(r'\s+', ' ', title_director).strip() # 去了回车换行空格之后的 片名 导演 print(date,score,title_director) # 打印 f.write(f"{date} {score} {title_director}\n") # 写入文件 f.write(f"\n---------------------------------{page}-----------------------------------------\n") print(f"============================【{type}】第{page}/{pagemax}页数据下载完成================================") print(f"{type}下载完成") -
![电影天堂某分类下的所有电影]() 电影天堂某分类下的所有电影 # -*- coding:utf-8 -*- # @time:2025/7/9 9:50 # @author:张旭辉 # @编辑器: PyCharm import time # 时间 import random # 随机数 import re # 正则表达式 一套规则 用于匹配符号条件的记录 from lxml import etree # 从lxml中导入etree 目的是为了解析网页源码 # 从myhttp.py文件中 导入模块 具体 函数是get_data from myhttp import get_data # 准备url 1 就是喜剧片的类型 第1页 url = "https://www.dytt8899.com/2/index.html" # 发送请求 response = get_data(url) # 获取数据 # 加载源码 html = etree.HTML(response.text) # xpath解析 # 获取当前类型电影的最大页码 类型转成int pagemax = int(html.xpath("//select/option[last()]/text()")[0].split(" ")[1]) for page in range(1,pagemax+1): time.sleep(random.randint(1,10))# 睡觉 单位秒 随机范围1-10秒 if page == 1: url = "https://www.dytt8899.com/1/index.html" else: url = f"https://www.dytt8899.com/1/index_{page}.html" print(f"============================正在下载第{page}页数据================================") # 再次发送请求 # 发送请求 response = get_data(url) # 获取数据 # 加载源码 html = etree.HTML(response.text) # 从第page页中取电影类型 type = ''.join(re.findall(r'[\u4e00-\u9fa5]+', html.xpath("//h1//font/text()")[0])) # 当前页的全部电影数据30条 tables = html.xpath("//div[@class='co_content8']/ul//table") with open(f"data/{type}.txt","a",encoding="utf-8") as f: f.write(f"\n---------------------------------{page}-----------------------------------------\n") for table in tables: date = table.xpath(".//tr[3]/td[2]/font[1]/text()")[0] # 日期 score = table.xpath(".//tr[3]/td[2]/font[2]/text()")[0] # 评分 score = re.sub(r'\s+', ' ', score).strip() # 去了回车换行空格之后的评分 title_director = table.xpath(".//tr[4]/td[1]/p[1]/text()")[0] # 片名 导演 title_director = re.sub(r'\s+', ' ', title_director).strip() # 去了回车换行空格之后的 片名 导演 print(date,score,title_director) # 打印 f.write(f"{date} {score} {title_director}\n") # 写入文件 f.write(f"\n---------------------------------{page}-----------------------------------------\n") print(f"============================第{page}页数据下载完成================================") print("下载完成")
电影天堂某分类下的所有电影 # -*- coding:utf-8 -*- # @time:2025/7/9 9:50 # @author:张旭辉 # @编辑器: PyCharm import time # 时间 import random # 随机数 import re # 正则表达式 一套规则 用于匹配符号条件的记录 from lxml import etree # 从lxml中导入etree 目的是为了解析网页源码 # 从myhttp.py文件中 导入模块 具体 函数是get_data from myhttp import get_data # 准备url 1 就是喜剧片的类型 第1页 url = "https://www.dytt8899.com/2/index.html" # 发送请求 response = get_data(url) # 获取数据 # 加载源码 html = etree.HTML(response.text) # xpath解析 # 获取当前类型电影的最大页码 类型转成int pagemax = int(html.xpath("//select/option[last()]/text()")[0].split(" ")[1]) for page in range(1,pagemax+1): time.sleep(random.randint(1,10))# 睡觉 单位秒 随机范围1-10秒 if page == 1: url = "https://www.dytt8899.com/1/index.html" else: url = f"https://www.dytt8899.com/1/index_{page}.html" print(f"============================正在下载第{page}页数据================================") # 再次发送请求 # 发送请求 response = get_data(url) # 获取数据 # 加载源码 html = etree.HTML(response.text) # 从第page页中取电影类型 type = ''.join(re.findall(r'[\u4e00-\u9fa5]+', html.xpath("//h1//font/text()")[0])) # 当前页的全部电影数据30条 tables = html.xpath("//div[@class='co_content8']/ul//table") with open(f"data/{type}.txt","a",encoding="utf-8") as f: f.write(f"\n---------------------------------{page}-----------------------------------------\n") for table in tables: date = table.xpath(".//tr[3]/td[2]/font[1]/text()")[0] # 日期 score = table.xpath(".//tr[3]/td[2]/font[2]/text()")[0] # 评分 score = re.sub(r'\s+', ' ', score).strip() # 去了回车换行空格之后的评分 title_director = table.xpath(".//tr[4]/td[1]/p[1]/text()")[0] # 片名 导演 title_director = re.sub(r'\s+', ' ', title_director).strip() # 去了回车换行空格之后的 片名 导演 print(date,score,title_director) # 打印 f.write(f"{date} {score} {title_director}\n") # 写入文件 f.write(f"\n---------------------------------{page}-----------------------------------------\n") print(f"============================第{page}页数据下载完成================================") print("下载完成") -
![梨视频视频爬取]() 梨视频视频爬取 # -*- coding:utf-8 -*- # @time:2025/7/8 10:10 # @author:张旭辉 # @file : zhang.py # @编辑器: PyCharm import requests def get_data(url): headers = { "user-agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/138.0.0.0 Safari/537.36", } response = requests.get(url=url,headers=headers) response.encoding = response.apparent_encoding return response def get_video_url(url,contId,params): headers = { "user-agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/138.0.0.0 Safari/537.36", "cookie":'PEAR_UUID=d6f6a867-a448-4561-9861-0170363cfa46; _uab_collina=175188032684858668947395; p_h5_u=EDC6CA6A-43EB-4E01-B161-70C22435000A; Hm_lvt_9707bc8d5f6bba210e7218b8496f076a=1751880327,1752203335; HMACCOUNT=15F47A8122133E49; Hm_lpvt_9707bc8d5f6bba210e7218b8496f076a=1752203336; tgw_l7_route=e0ec575606f95cc9ad003a83f9f8574f; JSESSIONID=7E3F76514FB7332116890EA82275AA69', "referer":f"https://www.pearvideo.com/video_{contId}" } # verify = False 发送get请求的时候 不去校验证书 response = requests.get(url=url,headers=headers,params=params) response.encoding = response.apparent_encoding return response # 准备当前页面url地址 url = "https://www.pearvideo.com/video_1801228" # 从url中获取当前视频的id contId = url.split("_")[-1] # 向指定服务器发送请求 video_url = "https://www.pearvideo.com/videoStatus.jsp" response = get_video_url(video_url,contId,params={"contId":contId}) # 获取视频假地址 srcUrl = response.json()['videoInfo']['videos']['srcUrl'] # 假地址: https://video.pearvideo.com/mp4/short/20250709/1752204172726-16056591-hd.mp4 print(srcUrl) # 真实地址:https://video.pearvideo.com/mp4/short/20250709/cont-1801228-16056591-hd.mp4 # 需要把 1752204172726 替换成 cont-1801228 # 1.根据srcUrl 提取对应的这串数字 fake = srcUrl.split('/')[-1].split('-')[0] print(fake) # 2.替换 real_video_url = srcUrl.replace(fake,f"cont-{contId}") print(real_video_url) # 向真实视频地址发送请求保存数据 response = get_data(real_video_url) # 下载到本地 print("正在下载") with open(f"{contId}.mp4","wb") as f: f.write(response.content) print("下载完成")
梨视频视频爬取 # -*- coding:utf-8 -*- # @time:2025/7/8 10:10 # @author:张旭辉 # @file : zhang.py # @编辑器: PyCharm import requests def get_data(url): headers = { "user-agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/138.0.0.0 Safari/537.36", } response = requests.get(url=url,headers=headers) response.encoding = response.apparent_encoding return response def get_video_url(url,contId,params): headers = { "user-agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/138.0.0.0 Safari/537.36", "cookie":'PEAR_UUID=d6f6a867-a448-4561-9861-0170363cfa46; _uab_collina=175188032684858668947395; p_h5_u=EDC6CA6A-43EB-4E01-B161-70C22435000A; Hm_lvt_9707bc8d5f6bba210e7218b8496f076a=1751880327,1752203335; HMACCOUNT=15F47A8122133E49; Hm_lpvt_9707bc8d5f6bba210e7218b8496f076a=1752203336; tgw_l7_route=e0ec575606f95cc9ad003a83f9f8574f; JSESSIONID=7E3F76514FB7332116890EA82275AA69', "referer":f"https://www.pearvideo.com/video_{contId}" } # verify = False 发送get请求的时候 不去校验证书 response = requests.get(url=url,headers=headers,params=params) response.encoding = response.apparent_encoding return response # 准备当前页面url地址 url = "https://www.pearvideo.com/video_1801228" # 从url中获取当前视频的id contId = url.split("_")[-1] # 向指定服务器发送请求 video_url = "https://www.pearvideo.com/videoStatus.jsp" response = get_video_url(video_url,contId,params={"contId":contId}) # 获取视频假地址 srcUrl = response.json()['videoInfo']['videos']['srcUrl'] # 假地址: https://video.pearvideo.com/mp4/short/20250709/1752204172726-16056591-hd.mp4 print(srcUrl) # 真实地址:https://video.pearvideo.com/mp4/short/20250709/cont-1801228-16056591-hd.mp4 # 需要把 1752204172726 替换成 cont-1801228 # 1.根据srcUrl 提取对应的这串数字 fake = srcUrl.split('/')[-1].split('-')[0] print(fake) # 2.替换 real_video_url = srcUrl.replace(fake,f"cont-{contId}") print(real_video_url) # 向真实视频地址发送请求保存数据 response = get_data(real_video_url) # 下载到本地 print("正在下载") with open(f"{contId}.mp4","wb") as f: f.write(response.content) print("下载完成") -
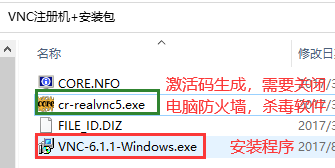
![VNC远程控制]()
-
![中国式英语]() 中国式英语 在中国,有这么一种神秘的语言,叫“Chinese English”。它言简意赅,生动有趣。简单中带着一丝繁复,调皮中又有着一缕文艺!我们中国人听了,常常眼神对视,就露出蜜汁微笑。“哦,我懂了,原来如此,竟然还TM可以这么说!”外国人却是一脸黑线。“what fuck!”这群中国人在搞什么鬼,我怎么听不懂?”1、you di da di da me,I hua la hua la you.滴水之恩,当涌泉相报2、Know is know, no know is no know, it s know.知之为知之,不知为不知!3、You roll as far as you can.有多远给我滚多远!4、If you want money, I have none; If you want life, I have one.老子要钱没有,要命一条!5、You are really a no three no four man.你真是一个不三不四的人!6、How are you ? 怎么是你?How old are you? 怎么老是你?7、We two who and who!老铁,咱两谁跟谁啊!8、You have seed. I will give you some color to see see. Brothers! Together up! 你有种,我给你点颜色看看,兄弟们,一起上。9、Horse horse tiger tiger. 马马虎虎10、you don’t bird me,I don’t bird you 你不鸟我,我也不鸟你。11、You Give Me Stop! 你给我站住!12、watch sister 表妹13、American Chinese not enough 美中不足14、Where cool where you stay!哪凉快上哪呆着15、heart flower angry open 心花怒放16、colour wolf 色狼17、People mountain and people sea. 人山人海18、Moring three night four.朝三暮四。19、no three no four 不三不四20、you have two down son。 你有两下子。21、let the horse come on 放马过来22、I give you face you don’t wanna face 给你脸你不要脸23、red face know me 红颜知己24、seven up eight down 七上八下25、you try try see!你试试看!26、love who who 爱谁谁27、go you mother's 去你妈28、May I borrow your light? 借光29、dragon born dragon,chicken born chicken,mouse’son can make hole!龙生龙,凤生凤,老鼠的儿子会打洞30、king eight eggs 王八蛋31、no care three seven twenty one 不管三七二十一32、go and look 走着瞧33、no money no talk 没钱免谈34、you me you me 彼此彼此35、you can kill me ,but you can`t fuck me -士可杀不可辱36、Long time no see。好久不见。37、People mountain people sea 人山人海38、No zuo no die 。不作就不会死。39、You can you up。你行你上。40、No can no BB (不行就别说话)
中国式英语 在中国,有这么一种神秘的语言,叫“Chinese English”。它言简意赅,生动有趣。简单中带着一丝繁复,调皮中又有着一缕文艺!我们中国人听了,常常眼神对视,就露出蜜汁微笑。“哦,我懂了,原来如此,竟然还TM可以这么说!”外国人却是一脸黑线。“what fuck!”这群中国人在搞什么鬼,我怎么听不懂?”1、you di da di da me,I hua la hua la you.滴水之恩,当涌泉相报2、Know is know, no know is no know, it s know.知之为知之,不知为不知!3、You roll as far as you can.有多远给我滚多远!4、If you want money, I have none; If you want life, I have one.老子要钱没有,要命一条!5、You are really a no three no four man.你真是一个不三不四的人!6、How are you ? 怎么是你?How old are you? 怎么老是你?7、We two who and who!老铁,咱两谁跟谁啊!8、You have seed. I will give you some color to see see. Brothers! Together up! 你有种,我给你点颜色看看,兄弟们,一起上。9、Horse horse tiger tiger. 马马虎虎10、you don’t bird me,I don’t bird you 你不鸟我,我也不鸟你。11、You Give Me Stop! 你给我站住!12、watch sister 表妹13、American Chinese not enough 美中不足14、Where cool where you stay!哪凉快上哪呆着15、heart flower angry open 心花怒放16、colour wolf 色狼17、People mountain and people sea. 人山人海18、Moring three night four.朝三暮四。19、no three no four 不三不四20、you have two down son。 你有两下子。21、let the horse come on 放马过来22、I give you face you don’t wanna face 给你脸你不要脸23、red face know me 红颜知己24、seven up eight down 七上八下25、you try try see!你试试看!26、love who who 爱谁谁27、go you mother's 去你妈28、May I borrow your light? 借光29、dragon born dragon,chicken born chicken,mouse’son can make hole!龙生龙,凤生凤,老鼠的儿子会打洞30、king eight eggs 王八蛋31、no care three seven twenty one 不管三七二十一32、go and look 走着瞧33、no money no talk 没钱免谈34、you me you me 彼此彼此35、you can kill me ,but you can`t fuck me -士可杀不可辱36、Long time no see。好久不见。37、People mountain people sea 人山人海38、No zuo no die 。不作就不会死。39、You can you up。你行你上。40、No can no BB (不行就别说话) -
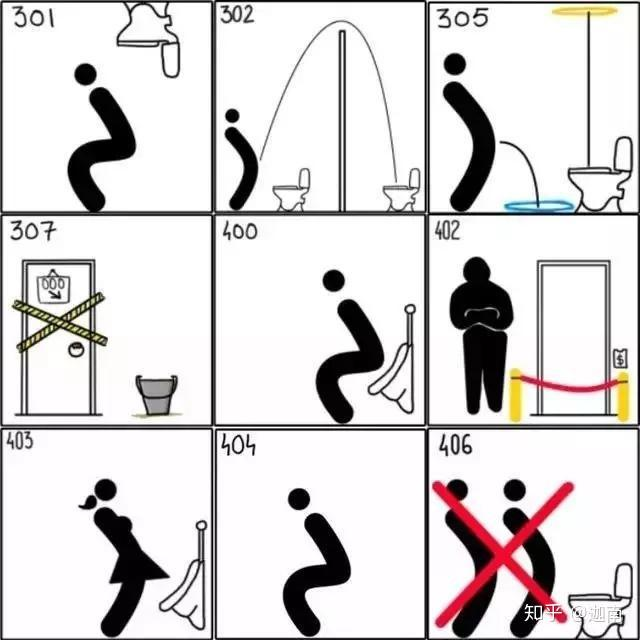
![HTTP状态码详解]() HTTP状态码详解 当浏览者访问一个网页时,浏览者的浏览器会向网页所在服务器发出请求。当浏览器接收并显示网页前,此网页所在的服务器会返回一个包含HTTP状态码的信息头(server header)用以响应浏览器的请求。HTTP状态码的英文为HTTP Status Code。下面是常见的HTTP状态码:200 - 请求成功301 - 资源(网页等)被永久转移到其它URL404 - 请求的资源(网页等)不存在500 - 内部服务器错误HTTP 状态代码表示什么意思?HTTP 状态码(英语:HTTP Status Code)是用以表示 HTTP 响应状态的 3 位数字代码。比如:1xx:消息2xx:成功3xx:重定向4xx:客户端错误5xx:服务器错误熟记这些状态码可以让我们在快速定位 Web 开发中遇到的问题、编写符合规范的接口服务,那么下面就让我们看看这些死板的 3 位数字都是什么意思。HTTP状态码分类HTTP状态码由三个十进制数字组成,第一个十进制数字定义了状态码的类型,后两个数字没有分类的作用。HTTP状态码共分为5种类型:1开头(信息响应)1xx(临时响应):信息性状态码,表示服务器已接收了客户端请求,客户端可继续发送请求。1xx(临时响应)表示临时响应并需要请求者继续执行操作的状态代码。代码 说明(继续) 请求者应当继续提出请求。 服务器返回此代码表示已收到请求的第一部分,正在等待其余部分。(切换协议) 请求者已要求服务器切换协议,服务器已确认并准备切换。2开头(成功响应)2xx (成功)表示成功处理了请求的状态代码。代码 说明(成功) 服务器已成功处理了请求。 通常,这表示服务器提供了请求的网页。(已创建) 请求成功并且服务器创建了新的资源。(已接受) 服务器已接受请求,但尚未处理。(非授权信息) 服务器已成功处理了请求,但返回的信息可能来自另一来源。(无内容) 服务器成功处理了请求,但没有返回任何内容。(重置内容) 服务器成功处理了请求,但没有返回任何内容。(部分内容) 服务器成功处理了部分 GET 请求。3开头(重定向)3xx (重定向) 表示要完成请求,需要进一步操作。 通常,这些状态代码用来重定向。(多种选择) 针对请求,服务器可执行多种操作。 服务器可根据请求者 (user agent) 选择一项操作,或提供操作列表供请求者选择。(永久移动) 请求的网页已永久移动到新位置。 服务器返回此响应(对 GET 或 HEAD 请求的响应)时,会自动将请求者转到新位置。(临时移动) 服务器目前从不同位置的网页响应请求,但请求者应继续使用原有位置来进行以后的请求。(查看其他位置) 请求者应当对不同的位置使用单独的 GET 请求来检索响应时,服务器返回此代码。(未修改) 自从上次请求后,请求的网页未修改过。 服务器返回此响应时,不会返回网页内容。(使用代理) 请求者只能使用代理访问请求的网页。 如果服务器返回此响应,还表示请求者应使用代理。(临时重定向) 服务器目前从不同位置的网页响应请求,但请求者应继续使用原有位置来进行以后的请求。4开头(客户端响应)4xx(请求错误) 这些状态代码表示请求可能出错,妨碍了服务器的处理。代码 说明(错误请求) 服务器不理解请求的语法。(未授权) 请求要求身份验证。 对于需要登录的网页,服务器可能返回此响应。(禁止) 服务器拒绝请求。(未找到) 服务器找不到请求的网页。(方法禁用) 禁用请求中指定的方法。(不接受) 无法使用请求的内容特性响应请求的网页。(需要代理授权) 此状态代码与 401(未授权)类似,但指定请求者应当授权使用代理。(请求超时) 服务器等候请求时发生超时。(冲突) 服务器在完成请求时发生冲突。 服务器必须在响应中包含有关冲突的信息。(已删除) 如果请求的资源已永久删除,服务器就会返回此响应。(需要有效长度) 服务器不接受不含有效内容长度标头字段的请求。(未满足前提条件) 服务器未满足请求者在请求中设置的其中一个前提条件。(请求实体过大) 服务器无法处理请求,因为请求实体过大,超出服务器的处理能力。(请求的 URI 过长) 请求的 URI(通常为网址)过长,服务器无法处理。(不支持的媒体类型) 请求的格式不受请求页面的支持。(请求范围不符合要求) 如果页面无法提供请求的范围,则服务器会返回此状态代码。(未满足期望值) 服务器未满足"期望"请求标头字段的要求。5开头(服务端响应)5xx(服务器错误)这些状态代码表示服务器在尝试处理请求时发生内部错误。 这些错误可能是服务器本身的错误,而不是请求出错。代码 说明(服务器内部错误) 服务器遇到错误,无法完成请求。(尚未实施) 服务器不具备完成请求的功能。 例如,服务器无法识别请求方法时可能会返回此代码。(错误网关) 服务器作为网关或代理,从上游服务器收到无效响应。(服务不可用) 服务器目前无法使用(由于超载或停机维护)。 通常,这只是暂时状态。(网关超时) 服务器作为网关或代理,但是没有及时从上游服务器收到请求。(HTTP 版本不受支持) 服务器不支持请求中所用的 HTTP 协议版本。趣味图解HTTP状态码的含义HTTP状态码(HTTP Status Code)是用以表示网页服务器HTTP响应状态的3位数字代码。我们可以通过查看HTTP状态码来判断服务器状态,常见的有404 、502等;但是其他不是很常见的状态码都代表什么状态呢?下面有两张有趣的图片,让你瞬间都能理解了。HTTP状态码(图一)301—永久移动。被请求的资源已被永久移动位置;302—请求的资源现在临时从不同的 URI 响应请求;305—使用代理。被请求的资源必须通过指定的代理才能被访问;307—临时跳转。被请求的资源在临时从不同的URL响应请求;400—错误请求;402—需要付款。该状态码是为了将来可能的需求而预留的,用于一些数字货币或者是微支付;403—禁止访问。服务器已经理解请求,但是拒绝执行它;404—找不到对象。请求失败,资源不存在;406—不可接受的。请求的资源的内容特性无法满足请求头中的条件,因而无法生成响应实体;HTTP状态码(图二)408—请求超时;409—冲突。由于和被请求的资源的当前状态之间存在冲突,请求无法完成;410—遗失的。被请求的资源在服务器上已经不再可用,而且没有任何已知的转发地址;413—响应实体太大。服务器拒绝处理当前请求,请求超过服务器所能处理和允许的最大值。417—期望失败。在请求头 Expect 中指定的预期内容无法被服务器满足;418—我是一个茶壶。超文本咖啡罐控制协议,但是并没有被实际的HTTP服务器实现;420—方法失效。422—不可处理的实体。请求格式正确,但是由于含有语义错误,无法响应;500—服务器内部错误。服务器遇到了一个未曾预料的状况,导致了它无法完成对请求的处理;最无耻的 HTTP 常用状态码图解之前有朋友发过一篇 HTTP 状态码大全,我补充一篇,也是网上偶然看见的图,觉得虽然很没有节操但是却很形象生动,分享出来共 High301 永久移动位置,被请求的资源已经被永久性的转移了位置 302 您请求的资源现在需要临时通过其他的 URI 来获取 305 使用代理,被请求的资源必须通过指定的代理才能访问到 307 临时跳转。被请求的资源在临时从不同的URL响应请求 400 请求错误 402 该状态码是为了将来可能的需求而预留的,比如可能用于一些数字货币或者是微支付 403 禁止访问。服务器已经理解请求,但是拒绝执行它 404 找不到对象。请求失败,资源不存在,程序员找对象简直是宇宙谜题 406 不可接受的。请求的资源的内容特性无法满足请求头中的条件,因而无法生成响应实体408 请求超时,请活活憋死吧 409 请求冲突。由于和被请求的资源的当前状态之间存在冲突,请求无法完成 410 遗失的。被请求的资源在服务器上已经不再可用,而且没有任何已知的转发地址 413 响应实体太大。服务器拒绝处理当前请求,请求超过服务器所能处理和允许的最大值 417 期望失败。在请求头 Expect 中指定的预期内容无法被服务器满足 418 我是一个茶壶。超文本咖啡罐控制协议,但是并没有被实际的HTTP服务器实现 420 方法失效 422 不可处理的实体。请求格式正确,但是由于含有语义错误,无法响应 500 服务器内部错误。服务器遇到了一个未曾预料的状况,导致了它无法完成对请求的处理一文牢记HTTP状态码(图解HTTP状态码)HTTP状态码是干什么的?HTTP状态码负责表示客户端HTTP请求的返回结果、标记服务器的处理是否正常、通知出现的错误等工作。状态码告知从服务器端返回的请求结果状态码的职责是当客户端向服务端发送请求时,描述返回的请求结果。借助状态吗,用户可以知道服务器端是正常处理了请求,还是出现了错误。2XX 成功状态码详述2XX的响应结果表明请求被正常处理了200 OK表示从客户端发来的请求在服务端被正常处理了。在响应报文内,随状态码一起返回的信息会因方法的不同而发生改变。比如,使用GET方法时,对应请求资源的实体会做为响应返回;而使用HEAD方法时,对应请求资源的实体首部不随报文主体作为响应返回(即在响应中只返回首部,不会返回时主体部分)。204 NoContent该状态码代表服务器接收的请求已成功处理,但在返回的响应报文中不含实体的主体部分。另外,也不允许返回任何实体的主体。比如,当从浏览器发出请求处理后,返回204响应,那么浏览器显示的页面不发生更新。一般在只需要从客户端往服务器发送信息,而对客户端不需要发送新信息内容的情况下使用。206 Partial Content该状态码表示服务端进行了范围请求,而服务器成功执行了这部分的GET请求。响应报文中包含Content-Range制定范围的实体内容。3XX 重定向3XX响应结果表明浏览器需要执行某些特殊的处理以正确处理请求。301 Moved Permanently永久重定向。该状态码表示请求的资源已被分配了新的URI,以后应使用资源现在所指的URI。也就是说,如果已经把资源对应的URI保存为书签了,这是应该按Location首部字段提示的URI重新保存。302 Found临时重定向。该状态码表示请求的资源已被分配了新的URI,希望用户(本次)能使用新的URI访问。和301状态码相似,但302状态码代表的资源不是被永久移动,只是临时性质的。换句话说,已移动的资源对应的URI将来还有可能会发生改变。303 See Other该状态码表示由于请求对应的资源存在着另一个URI,应使用GET方法定向获取请求的资源。303状态码和302状态码有着相同的功能,但303状态码明确表示客户端应采用GET方法获取资源,这点与302状态码有区别。301,302,303之间的联系当301、302、303响应状态码返回时,几乎所有的浏览器都会把POST改成GET,并删除请求报文内的主体,之后请求会自动再次发送。301,302标准是禁止将POST方法改变成FET方法,但实际使用时大家都会这么做。304 Not Modified该状态码表示客户端发送附带条件的请求时,服务器允许请求访问资源,但未满足条件的情况。304状态码返回时,不包含任何响应的主体部分。304虽然被划分在3XX类别中,但是和重定向没有关系。307 Temporary Redirect临时重定向。该状态码与302有着相同的含义。尽管302标准禁止POST变换成GET,但实际使用时大家并不遵守。307会遵照浏览器标准,不会从POST变成GET。但是,对于处理响应时的行为,每种浏览器有可能出现不同的情况。4XX 客户端错误4XX的响应结果表明客户端时发生错误的原因所在。400 Bad Request该状态码表示请求报文中存在语法错误。当错误发生时,需修改请求的内容后再次发送请求。另外,浏览器会像200 OK一样对待该状态码。401 Unauthorized该状态码表示发送请求需要有通过HTTP认证(BASIC认证、DIGEST认证)的认证信息。另外若之前已进行过1次请求,则表示用户认证失败。返回含有401的响应必须包含一个适用于被请求资源的WWW-Authenticate首部用于质询(challenge)用户信息。当浏览器初次接收到401响应,会弹出认证用的对话窗口。403 Forbidden该状态码表明对请求资源的访问被服务器拒绝了。服务器没有必要给出拒绝的详细理由,但如果想做说明的话,可以在实体的主体部分对原因进行描述,这样就能让用户看到。未获得文件系统的访问授权,访问权限出现某些问题(从未授权的发送源IP地址试图访问)等列举的情况都有可能是发生403的原因。404 Not Found该状态码表示服务器上无法找到请求的资源。除此之外,也可以在服务器端拒绝请求且不想说明理由时使用。5XX 服务器错误5XX的响应结果表明服务器本身发生错误。500 Internal Server Error该状态码表明服务器端在执行请求时发生了错误。也有可能是Web应用存在的bug或某些临时的故障。503 Service Unavailable
HTTP状态码详解 当浏览者访问一个网页时,浏览者的浏览器会向网页所在服务器发出请求。当浏览器接收并显示网页前,此网页所在的服务器会返回一个包含HTTP状态码的信息头(server header)用以响应浏览器的请求。HTTP状态码的英文为HTTP Status Code。下面是常见的HTTP状态码:200 - 请求成功301 - 资源(网页等)被永久转移到其它URL404 - 请求的资源(网页等)不存在500 - 内部服务器错误HTTP 状态代码表示什么意思?HTTP 状态码(英语:HTTP Status Code)是用以表示 HTTP 响应状态的 3 位数字代码。比如:1xx:消息2xx:成功3xx:重定向4xx:客户端错误5xx:服务器错误熟记这些状态码可以让我们在快速定位 Web 开发中遇到的问题、编写符合规范的接口服务,那么下面就让我们看看这些死板的 3 位数字都是什么意思。HTTP状态码分类HTTP状态码由三个十进制数字组成,第一个十进制数字定义了状态码的类型,后两个数字没有分类的作用。HTTP状态码共分为5种类型:1开头(信息响应)1xx(临时响应):信息性状态码,表示服务器已接收了客户端请求,客户端可继续发送请求。1xx(临时响应)表示临时响应并需要请求者继续执行操作的状态代码。代码 说明(继续) 请求者应当继续提出请求。 服务器返回此代码表示已收到请求的第一部分,正在等待其余部分。(切换协议) 请求者已要求服务器切换协议,服务器已确认并准备切换。2开头(成功响应)2xx (成功)表示成功处理了请求的状态代码。代码 说明(成功) 服务器已成功处理了请求。 通常,这表示服务器提供了请求的网页。(已创建) 请求成功并且服务器创建了新的资源。(已接受) 服务器已接受请求,但尚未处理。(非授权信息) 服务器已成功处理了请求,但返回的信息可能来自另一来源。(无内容) 服务器成功处理了请求,但没有返回任何内容。(重置内容) 服务器成功处理了请求,但没有返回任何内容。(部分内容) 服务器成功处理了部分 GET 请求。3开头(重定向)3xx (重定向) 表示要完成请求,需要进一步操作。 通常,这些状态代码用来重定向。(多种选择) 针对请求,服务器可执行多种操作。 服务器可根据请求者 (user agent) 选择一项操作,或提供操作列表供请求者选择。(永久移动) 请求的网页已永久移动到新位置。 服务器返回此响应(对 GET 或 HEAD 请求的响应)时,会自动将请求者转到新位置。(临时移动) 服务器目前从不同位置的网页响应请求,但请求者应继续使用原有位置来进行以后的请求。(查看其他位置) 请求者应当对不同的位置使用单独的 GET 请求来检索响应时,服务器返回此代码。(未修改) 自从上次请求后,请求的网页未修改过。 服务器返回此响应时,不会返回网页内容。(使用代理) 请求者只能使用代理访问请求的网页。 如果服务器返回此响应,还表示请求者应使用代理。(临时重定向) 服务器目前从不同位置的网页响应请求,但请求者应继续使用原有位置来进行以后的请求。4开头(客户端响应)4xx(请求错误) 这些状态代码表示请求可能出错,妨碍了服务器的处理。代码 说明(错误请求) 服务器不理解请求的语法。(未授权) 请求要求身份验证。 对于需要登录的网页,服务器可能返回此响应。(禁止) 服务器拒绝请求。(未找到) 服务器找不到请求的网页。(方法禁用) 禁用请求中指定的方法。(不接受) 无法使用请求的内容特性响应请求的网页。(需要代理授权) 此状态代码与 401(未授权)类似,但指定请求者应当授权使用代理。(请求超时) 服务器等候请求时发生超时。(冲突) 服务器在完成请求时发生冲突。 服务器必须在响应中包含有关冲突的信息。(已删除) 如果请求的资源已永久删除,服务器就会返回此响应。(需要有效长度) 服务器不接受不含有效内容长度标头字段的请求。(未满足前提条件) 服务器未满足请求者在请求中设置的其中一个前提条件。(请求实体过大) 服务器无法处理请求,因为请求实体过大,超出服务器的处理能力。(请求的 URI 过长) 请求的 URI(通常为网址)过长,服务器无法处理。(不支持的媒体类型) 请求的格式不受请求页面的支持。(请求范围不符合要求) 如果页面无法提供请求的范围,则服务器会返回此状态代码。(未满足期望值) 服务器未满足"期望"请求标头字段的要求。5开头(服务端响应)5xx(服务器错误)这些状态代码表示服务器在尝试处理请求时发生内部错误。 这些错误可能是服务器本身的错误,而不是请求出错。代码 说明(服务器内部错误) 服务器遇到错误,无法完成请求。(尚未实施) 服务器不具备完成请求的功能。 例如,服务器无法识别请求方法时可能会返回此代码。(错误网关) 服务器作为网关或代理,从上游服务器收到无效响应。(服务不可用) 服务器目前无法使用(由于超载或停机维护)。 通常,这只是暂时状态。(网关超时) 服务器作为网关或代理,但是没有及时从上游服务器收到请求。(HTTP 版本不受支持) 服务器不支持请求中所用的 HTTP 协议版本。趣味图解HTTP状态码的含义HTTP状态码(HTTP Status Code)是用以表示网页服务器HTTP响应状态的3位数字代码。我们可以通过查看HTTP状态码来判断服务器状态,常见的有404 、502等;但是其他不是很常见的状态码都代表什么状态呢?下面有两张有趣的图片,让你瞬间都能理解了。HTTP状态码(图一)301—永久移动。被请求的资源已被永久移动位置;302—请求的资源现在临时从不同的 URI 响应请求;305—使用代理。被请求的资源必须通过指定的代理才能被访问;307—临时跳转。被请求的资源在临时从不同的URL响应请求;400—错误请求;402—需要付款。该状态码是为了将来可能的需求而预留的,用于一些数字货币或者是微支付;403—禁止访问。服务器已经理解请求,但是拒绝执行它;404—找不到对象。请求失败,资源不存在;406—不可接受的。请求的资源的内容特性无法满足请求头中的条件,因而无法生成响应实体;HTTP状态码(图二)408—请求超时;409—冲突。由于和被请求的资源的当前状态之间存在冲突,请求无法完成;410—遗失的。被请求的资源在服务器上已经不再可用,而且没有任何已知的转发地址;413—响应实体太大。服务器拒绝处理当前请求,请求超过服务器所能处理和允许的最大值。417—期望失败。在请求头 Expect 中指定的预期内容无法被服务器满足;418—我是一个茶壶。超文本咖啡罐控制协议,但是并没有被实际的HTTP服务器实现;420—方法失效。422—不可处理的实体。请求格式正确,但是由于含有语义错误,无法响应;500—服务器内部错误。服务器遇到了一个未曾预料的状况,导致了它无法完成对请求的处理;最无耻的 HTTP 常用状态码图解之前有朋友发过一篇 HTTP 状态码大全,我补充一篇,也是网上偶然看见的图,觉得虽然很没有节操但是却很形象生动,分享出来共 High301 永久移动位置,被请求的资源已经被永久性的转移了位置 302 您请求的资源现在需要临时通过其他的 URI 来获取 305 使用代理,被请求的资源必须通过指定的代理才能访问到 307 临时跳转。被请求的资源在临时从不同的URL响应请求 400 请求错误 402 该状态码是为了将来可能的需求而预留的,比如可能用于一些数字货币或者是微支付 403 禁止访问。服务器已经理解请求,但是拒绝执行它 404 找不到对象。请求失败,资源不存在,程序员找对象简直是宇宙谜题 406 不可接受的。请求的资源的内容特性无法满足请求头中的条件,因而无法生成响应实体408 请求超时,请活活憋死吧 409 请求冲突。由于和被请求的资源的当前状态之间存在冲突,请求无法完成 410 遗失的。被请求的资源在服务器上已经不再可用,而且没有任何已知的转发地址 413 响应实体太大。服务器拒绝处理当前请求,请求超过服务器所能处理和允许的最大值 417 期望失败。在请求头 Expect 中指定的预期内容无法被服务器满足 418 我是一个茶壶。超文本咖啡罐控制协议,但是并没有被实际的HTTP服务器实现 420 方法失效 422 不可处理的实体。请求格式正确,但是由于含有语义错误,无法响应 500 服务器内部错误。服务器遇到了一个未曾预料的状况,导致了它无法完成对请求的处理一文牢记HTTP状态码(图解HTTP状态码)HTTP状态码是干什么的?HTTP状态码负责表示客户端HTTP请求的返回结果、标记服务器的处理是否正常、通知出现的错误等工作。状态码告知从服务器端返回的请求结果状态码的职责是当客户端向服务端发送请求时,描述返回的请求结果。借助状态吗,用户可以知道服务器端是正常处理了请求,还是出现了错误。2XX 成功状态码详述2XX的响应结果表明请求被正常处理了200 OK表示从客户端发来的请求在服务端被正常处理了。在响应报文内,随状态码一起返回的信息会因方法的不同而发生改变。比如,使用GET方法时,对应请求资源的实体会做为响应返回;而使用HEAD方法时,对应请求资源的实体首部不随报文主体作为响应返回(即在响应中只返回首部,不会返回时主体部分)。204 NoContent该状态码代表服务器接收的请求已成功处理,但在返回的响应报文中不含实体的主体部分。另外,也不允许返回任何实体的主体。比如,当从浏览器发出请求处理后,返回204响应,那么浏览器显示的页面不发生更新。一般在只需要从客户端往服务器发送信息,而对客户端不需要发送新信息内容的情况下使用。206 Partial Content该状态码表示服务端进行了范围请求,而服务器成功执行了这部分的GET请求。响应报文中包含Content-Range制定范围的实体内容。3XX 重定向3XX响应结果表明浏览器需要执行某些特殊的处理以正确处理请求。301 Moved Permanently永久重定向。该状态码表示请求的资源已被分配了新的URI,以后应使用资源现在所指的URI。也就是说,如果已经把资源对应的URI保存为书签了,这是应该按Location首部字段提示的URI重新保存。302 Found临时重定向。该状态码表示请求的资源已被分配了新的URI,希望用户(本次)能使用新的URI访问。和301状态码相似,但302状态码代表的资源不是被永久移动,只是临时性质的。换句话说,已移动的资源对应的URI将来还有可能会发生改变。303 See Other该状态码表示由于请求对应的资源存在着另一个URI,应使用GET方法定向获取请求的资源。303状态码和302状态码有着相同的功能,但303状态码明确表示客户端应采用GET方法获取资源,这点与302状态码有区别。301,302,303之间的联系当301、302、303响应状态码返回时,几乎所有的浏览器都会把POST改成GET,并删除请求报文内的主体,之后请求会自动再次发送。301,302标准是禁止将POST方法改变成FET方法,但实际使用时大家都会这么做。304 Not Modified该状态码表示客户端发送附带条件的请求时,服务器允许请求访问资源,但未满足条件的情况。304状态码返回时,不包含任何响应的主体部分。304虽然被划分在3XX类别中,但是和重定向没有关系。307 Temporary Redirect临时重定向。该状态码与302有着相同的含义。尽管302标准禁止POST变换成GET,但实际使用时大家并不遵守。307会遵照浏览器标准,不会从POST变成GET。但是,对于处理响应时的行为,每种浏览器有可能出现不同的情况。4XX 客户端错误4XX的响应结果表明客户端时发生错误的原因所在。400 Bad Request该状态码表示请求报文中存在语法错误。当错误发生时,需修改请求的内容后再次发送请求。另外,浏览器会像200 OK一样对待该状态码。401 Unauthorized该状态码表示发送请求需要有通过HTTP认证(BASIC认证、DIGEST认证)的认证信息。另外若之前已进行过1次请求,则表示用户认证失败。返回含有401的响应必须包含一个适用于被请求资源的WWW-Authenticate首部用于质询(challenge)用户信息。当浏览器初次接收到401响应,会弹出认证用的对话窗口。403 Forbidden该状态码表明对请求资源的访问被服务器拒绝了。服务器没有必要给出拒绝的详细理由,但如果想做说明的话,可以在实体的主体部分对原因进行描述,这样就能让用户看到。未获得文件系统的访问授权,访问权限出现某些问题(从未授权的发送源IP地址试图访问)等列举的情况都有可能是发生403的原因。404 Not Found该状态码表示服务器上无法找到请求的资源。除此之外,也可以在服务器端拒绝请求且不想说明理由时使用。5XX 服务器错误5XX的响应结果表明服务器本身发生错误。500 Internal Server Error该状态码表明服务器端在执行请求时发生了错误。也有可能是Web应用存在的bug或某些临时的故障。503 Service Unavailable -
![奇葩代码注释]()
-
![gitbook入门]() gitbook入门 gitbook 生成电子书主要有三种方式:gitbook-cli 命令行操作,简洁高效,适合从事软件开发的相关人员.gitbook-editor 编辑器操作,可视化编辑,适合无编程经验的文学创作者.gitbook.com 官网操作,在线编辑实时发布,适合无本地环境且科学上网的体验者.本文主要讲解第一种 gitbook-cli 命令行操作流程gitbook 的一些常用命令安装 gitbook-cli 脚手架工具本机已安装 node.js 开发环境,安装完成后运行 gitbook -V 能够打印出版本信息,则表示安装成功.1.创建文件夹用于存放电子书(md)文件2.输入cmd进入命令行3.安装gitbook客户端npm install -g gitbook-cli 4.初始化 gitbook 项目gitbook init 初始化项目,按照 gitbook 规范会自动创建 README.md 和 SUMMARY.md 两个文件SUMMARY.md 是电子书的章节目录,gitbook 会初始化相应的文件目录结构,所以主要是用于开发初始阶段.打开polyfills.js文件,找到这个函数看注释应该用来处理旧版本的问题,查看这个方法的调用位置发现在61-63行再次执行 gitbook init # Summary * [Introduction](INTRODUCTION.md) * [Chapter 1](CHAPTER1.md) * [Section 1.1](CHAPTER1_SECTION1.md) * [Section 1.2](CHAPTER1_SECTION2.md) * [Chapter 2](CHAPTER2.md) * [Section 2.1](CHAPTER2_SECTION1.md) * [Section 2.2](CHAPTER2_SECTION2.md) * [Conclusion](CONCLUSION.md) 5.启动 gitbook 项目gitbook serve启动本地服务,程序无报错则可以在浏览器预览电子书效果: http://localhost:4000由于能够实时预览电子书效果,并且大多数开发环境搭建在本地而不是远程服务器中,所以主要用于开发调试阶段.重启启动本地服务,查看修改后的内容,手动创建对应md文件6.构建 gitbook 静态网页构建静态网页而不启动本地服务器,默认生成文件存放在 _book/ 目录,当然输出目录是可配置的,暂不涉及输出静态网页后可打包上传到服务器,也可以上传到 github 等网站进行托管,因而主要用于发布准备阶段.gitbook build章节小结gitbook init 初始化 README.md 和 SUMMARY.md 两个文件.gitbook build 本地构建但不运行服务,默认输出到 _book/ 目录.gitbook serve 本地构建并运行服务,默认访问 http://localhost:4000 实时预览.
gitbook入门 gitbook 生成电子书主要有三种方式:gitbook-cli 命令行操作,简洁高效,适合从事软件开发的相关人员.gitbook-editor 编辑器操作,可视化编辑,适合无编程经验的文学创作者.gitbook.com 官网操作,在线编辑实时发布,适合无本地环境且科学上网的体验者.本文主要讲解第一种 gitbook-cli 命令行操作流程gitbook 的一些常用命令安装 gitbook-cli 脚手架工具本机已安装 node.js 开发环境,安装完成后运行 gitbook -V 能够打印出版本信息,则表示安装成功.1.创建文件夹用于存放电子书(md)文件2.输入cmd进入命令行3.安装gitbook客户端npm install -g gitbook-cli 4.初始化 gitbook 项目gitbook init 初始化项目,按照 gitbook 规范会自动创建 README.md 和 SUMMARY.md 两个文件SUMMARY.md 是电子书的章节目录,gitbook 会初始化相应的文件目录结构,所以主要是用于开发初始阶段.打开polyfills.js文件,找到这个函数看注释应该用来处理旧版本的问题,查看这个方法的调用位置发现在61-63行再次执行 gitbook init # Summary * [Introduction](INTRODUCTION.md) * [Chapter 1](CHAPTER1.md) * [Section 1.1](CHAPTER1_SECTION1.md) * [Section 1.2](CHAPTER1_SECTION2.md) * [Chapter 2](CHAPTER2.md) * [Section 2.1](CHAPTER2_SECTION1.md) * [Section 2.2](CHAPTER2_SECTION2.md) * [Conclusion](CONCLUSION.md) 5.启动 gitbook 项目gitbook serve启动本地服务,程序无报错则可以在浏览器预览电子书效果: http://localhost:4000由于能够实时预览电子书效果,并且大多数开发环境搭建在本地而不是远程服务器中,所以主要用于开发调试阶段.重启启动本地服务,查看修改后的内容,手动创建对应md文件6.构建 gitbook 静态网页构建静态网页而不启动本地服务器,默认生成文件存放在 _book/ 目录,当然输出目录是可配置的,暂不涉及输出静态网页后可打包上传到服务器,也可以上传到 github 等网站进行托管,因而主要用于发布准备阶段.gitbook build章节小结gitbook init 初始化 README.md 和 SUMMARY.md 两个文件.gitbook build 本地构建但不运行服务,默认输出到 _book/ 目录.gitbook serve 本地构建并运行服务,默认访问 http://localhost:4000 实时预览.